How Airbnb built a lightweight workflow engine to solve durable execution.
By: Ricardo Gamba, Andriy Sergiyenko
Introduction: The durable execution problem
Picture this hypothetical flow: A host submits an insurance claim about their listing to Airbnb. The system needs to validate the claim, run trust and safety checks, assess estimates, process the payout, and send notifications. Halfway through — after the validation passes, but before the payout — the server crashes.
What happens next?
In a traditional architecture, the answer is often “it depends.” Maybe the operation times out and the guest retries, triggering duplicate processing. Maybe partial state corrupts what comes next. And for workflows spanning minutes, hours, or even days, such as our insurance claim example, interruptions are all too likely.
The industry has developed solutions for this, such as dedicated orchestration clusters and cloud-managed workflow services. However, these solutions come with their own costs: operational complexity, infrastructure dependencies, and architectural constraints.
We needed durable execution without the overhead. This article describes how we built Skipper, an embedded workflow engine now powering critical workflows across insurance, payments, media processing, and infrastructure automation at Airbnb.
Why existing solutions fall short
Before building Skipper, we evaluated existing workflow solutions extensively. Each had merits, but none fit our specific constraints.
The external orchestration problem
External orchestration engines are the industry gold standard for durable workflow execution, providing exactly-once semantics and battle-tested reliability. However, they require dedicated infrastructure — a cluster of servers and a persistence layer, along with operational expertise — to maintain. For our highest-criticality, “Tier 0” services (services which directly impact user-facing transactions), adding a new critical dependency was problematic. An orchestration cluster outage would mean every dependent service would lose the ability to start or advance workflows.
Cloud-managed workflow services eliminate operational overhead but introduce vendor lock-in, regulatory and data-handling requirements beyond our own infrastructure, limits on execution, and the same fundamental concern: a critical external dependency.
Meanwhile, homegrown, queue-based systems avoid external dependencies but trade them for bespoke complexity: each team implementing and maintaining its own retry logic, state management, and compensation flows.
The domain logic problem
Beyond the infrastructure problems, we noticed something subtler; and this isn’t unique to Airbnb, it’s an industry-wide pattern. When teams wire up multi-step processes using queues or ad-hoc async plumbing, the domain logic ends up fragmented. A single business workflow, such as processing an insurance claim, gets scattered across queue consumers, scheduled jobs, callback endpoints, and reconciliation scripts. There’s no single place in the code where you can read what the business process actually does. And to make things worse, each of these fragments tangles domain rules together with infrastructure concerns: retry backoff, deduplication checks, timeout handling, async coordination.
Why we built Skipper
Across Airbnb, teams were running into the same problem independently when trying to solve durable execution. In each case, engineers built something bespoke. These solutions worked, but they shared the same issues: they were expensive to build, difficult to test, and each one re-discovered the same edge cases around idempotency, partial failure, and crash recovery. We were paying the cost of solving durable execution over and over again, and every new implementation carried its own set of subtle bugs.
We stepped back and looked at the pattern as a whole. Instead of having every service re-invent this wheel, we decided to build a shared library. Skipper is a workflow engine that can be embedded directly into any service, with succinct ergonomics, no external runtime dependency, and allowing developers to focus on writing domain logic instead of plumbing code.
Skipper doesn’t enforce architectural purity, but its programming model promotes it. By exposing workflows and actions as plain Java/Kotlin classes, with a minimal, annotation-based contract, Skipper enables developers to write business logic that looks like business logic, not framework boilerplate.
Primitives such as conditional waits, durable retries, and signals are available, but they surface through the same straightforward class structure, rather than requiring developers to learn a separate execution model or wire up infrastructure abstractions. The contract stays out of the way: a workflow method reads like the process it represents, and an action method looks like the service call it wraps. And, because domain rules are cohesive in a single class rather than scattered across infrastructure components, it becomes straightforward to test workflows end-to-end.
Here’s what that looks like in practice: a durable, multi-step business process expressed as a single workflow class, with side effects isolated behind actions and one annotation:
// 1) Invoke it like a normal typed call (no codegen client)
val out = workflow<ChargeAndAccept>("reservation:${req.id}").execute(req)
// 2) Define workflow logic as normal-looking Kotlin
class ChargeAndAccept : Workflow() {
private val billing = actions<BillingActions>()
private val reservations = actions<ReservationActions>()
@StateParam var paymentCaptured = false
@WorkflowMethod
suspend fun execute(r0: Reservation): Reservation {
val r1 = billing.charge(r0) // durable side-effect boundary
waitUntil { paymentCaptured } // durable wait (resumes after restart)
return reservations.markAccepted(r1)
}
}
// 3) Side effects live in Actions; one annotation makes it checkpointable
class BillingActions : Actions() {
@Execute(checkpoint = true)
suspend fun charge(r: Reservation): Reservation =
billingApi.chargeAsync(r.id, r.amount).await()
}
Skipper isn’t the first system to offer “write normal code, get durable execution” — other workflow engines do as well — but Skipper’s focus is on removing the adoption friction: fewer required constructs and less setup, so teams that use Java/Kotlin can get to a first durable workflow with minimal ceremony.
Our requirements
We crystallized our requirements through these evaluations:
- No new critical dependencies: Tier 0 services cannot add single points of failure
- Leverage existing infrastructure: Use the database the service already depends on
- Self-service integration: Enable teams to adopt Skipper without dedicated support
- Simple programming model: Support rapid development and easy maintenance
- Performance neutrality: The workflow engine shouldn’t constrain host service scalability
These requirements pointed toward an embedded architecture: a library that runs within each service, rather than a central orchestration system.
Design philosophy
Five principles guided Skipper’s design.
Succinct ergonomics. Workflow code should read like the business logic it represents. A workflow that “waits for approval, then processes payment, then sends confirmation” should look just like that in code.
No single point of failure. Skipper runs embedded within each host service. If one service’s workflow processing fails, other services continue independently. There’s no central coordinator that can bring everything down.
Leverage existing dependencies. Skipper stores its state in the same database the host service already uses: either MySQL or Airbnb’s internal Unified Data Store. There’s no separate persistence layer to manage.
Self-service ready. Skipper is a library dependency: add it to your build, provide some configuration, and start defining workflows. No complex setup, no dependencies on a central team.
Performance-neutral. Skipper uses separate thread pools, configurable concurrency limits, and efficient hibernation patterns to coexist peacefully with latency-sensitive request handling.
How Skipper works
Skipper’s programming model centers on two abstractions: Workflows and Actions. Workflows define the orchestration logic: what happens in what order, and under what conditions. Actions encapsulate individual operations such as API calls, database updates, notifications. Each action is automatically checkpointed, so the result of an action survives crashes and restarts.
A workflow in practice
On the Airbnb platform, hosts submit photos of their property listings that go through a review process before the listing can go live. In this fictional example, a host submits their photos to be approved for quality and accuracy, then the listing is activated; then, if all looks good, the host is notified. This simplified fictional workflow demonstrates the core concepts of Skipper in action:
class ListingPublicationWorkflow : Workflow() {
private val actions = actions<ListingActions>();
@StateField val photosApproved: Boolean? = false;
@WorkflowMethod
suspend fun publishListing(submission: ListingSubmission): PublicationResult {
// Submit photos for review
val reviewId = actions.submitPhotosForReview(submission.getListingId());
// Wait for photo review completion (manual or automated)
val reviewTimedOut = waitUntil(() -> photosApproved != null,
Duration.ofHours(24));
if (reviewTimedOut || !photosApproved) {
actions.notifyHost(submission.getHostId(), "Photos require updates");
return PublicationResult.rejected("Photo review failed");
}
// Publish the listing
actions.activateListing(submission.getListingId());
actions.notifyHost(submission.getHostId(), "Your listing is now live!");
return PublicationResult.success(submission.getListingId());
}
@SignalMethod
fun completePhotoReview(approved: Boolean) {
photosApproved = approved;
}
}
This code reads naturally: submit photos, wait for photo review, publish. There’s no retry logic, queue management, or async coordination visible in the workflow itself. Signals (@SignalMethod) let external events push data into a running workflow, updating @StateField fields that the workflow’s waitUntil conditions evaluate against.
The following diagram shows how these components interact at runtime:
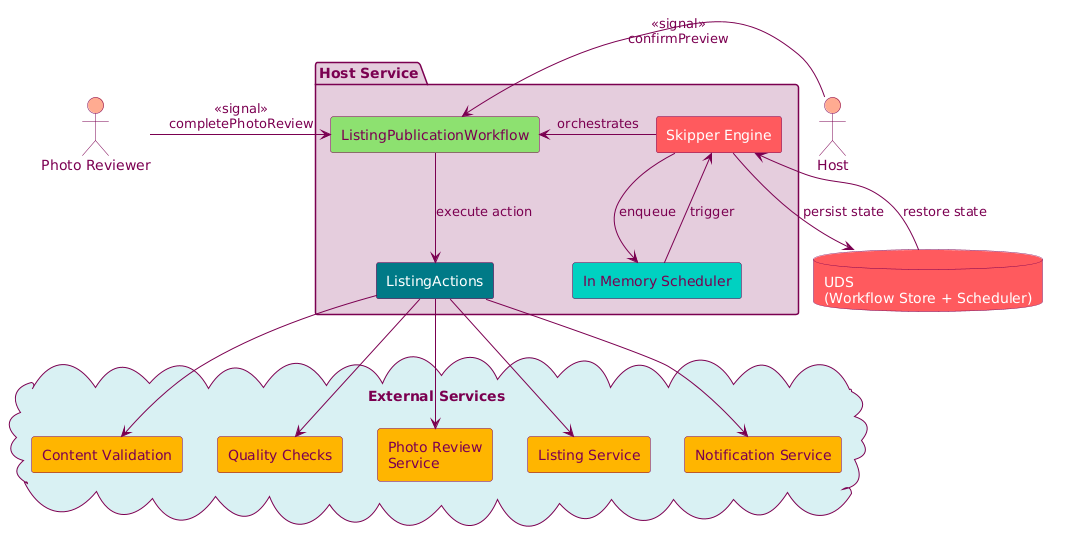
Because domain logic is cohesive in a single class, testing is equally straightforward; no queues to set up, no infrastructure to mock:
class ListingPublicationTest : SkipperTest() {
@Test
fun testListingPublication() {
val workflow = workflowBuilder(ListingPublicationWorkflow::class.java).build();
workflow.publishListing(ListingSubmission("listing-123", "host-456", true));
helper.expectWorkflowToWait(); // workflow waits for photo review
workflow.completePhotoReview(true); // photos approved
helper.waitForWorkflowToComplete();
val result = workflow.getResult();
assertEquals(PublicationResult.Status.SUCCESS, result.getStatus());
}
}
Replay: How durability works
Skipper achieves durability through its replay mechanism with checkpointed actions. When a workflow starts, Skipper executes the workflow method and checkpoints each action’s result to the database. If the workflow needs to wait (via waitUntil), Skipper persists the current state and the workflow hibernates, consuming no compute resources.
When conditions change — a signal arrives, a timer expires, or the service restarts — Skipper replays the workflow method from the beginning. Previously executed actions don’t re-execute; they return their checkpointed results instantly. The workflow picks up from where it left off.
Unlike event-sourced orchestration systems that reconstruct state by replaying an entire event history, Skipper persists state fields directly. There’s no event log to replay, just current state and checkpointed action results. This makes execution leaner, especially for workflows with many signals or long histories, though it trades some auditability for that efficiency. The next section explains how this also translates to minimal runtime overhead in the most common case.
The happy path: Getting out of the way
Most workflow engines impose overhead on every execution, even when nothing goes wrong. External orchestration engines require network round-trips to a central cluster for every activity invocation — the worker executes the activity, then calls back to the cluster to persist the result before the workflow can advance. This is fundamental to their architecture; the cluster is the coordinator.
Skipper takes a different approach. When a workflow starts, two things happen at the database level: the workflow instance is created, and a delayed timeout task is scheduled as a durability guarantee. Then the workflow executes entirely in-process. Actions run as normal method calls on an in-memory execution queue on a dedicated thread pool, checkpoints are batched, and the workflow can run to completion without any further coordination.
The delayed task acts as a safety net: if the process crashes mid-execution, the persistent scheduler picks up the workflow after a lease period expires and replays it. If the workflow completes normally, the timeout task fires harmlessly and is discarded.
The result is that, in the happy case: the workflow runs and all actions succeed, with no crashes; Skipper adds very little overhead (just a few database writes). The workflow executes almost as if there were no workflow engine at all. The engine is only called into action when something goes wrong: a crash triggers a replay, a waitUntil hibernates the workflow, or an error invokes compensation.
This is what makes Skipper viable for latency-sensitive, high-throughput services — durability is guaranteed, but you only pay for it when you need it.
The determinism requirement
Replay imposes one key constraint: workflow methods must be deterministic. Given the same inputs, checkpointed action results, and state fields, the workflow must make the same decisions and call actions in the same order. All side effects, such as API calls, time-dependent logic, and randomness, belong in actions, never in the workflow method directly.
Error handling and compensation
Skipper distinguishes between retryable errors (temporary failures such as network timeouts, which are retried automatically, with configurable backoff) and non-retryable errors (permanent failures such as a declined card, which halt the workflow’s normal flow).
When a workflow fails partway through, you’re left in an awkward state: some actions completed successfully, but the workflow as a whole didn’t. For example, a listing might pass content validation and quality checks, but then fail during photo review submission.
The content validation result is now dangling; the work was done in preparation for a publication that now isn’t going to happen. In traditional architectures, teams handle this with ad-hoc cleanup logic: a scheduled job that scans for orphaned records, a reconciliation script that runs nightly, or manual intervention. These approaches are fragile, often delayed, and easy to forget as the workflow evolves.
We made compensation a first-class primitive to prevent workflow code from getting cluttered with error-handling plumbing that obscures the business logic. The @Compensate annotation lets developers pair each action with a method that undoes its effect. If an action fails after prior actions have succeeded, Skipper automatically executes compensation methods in reverse order (releasing held inventory, refunding charges, reverting state changes), walking the system back to a consistent state. Developers express what “undo” means for each action; Skipper handles the orchestration of when and in what order the undos run. The result is eventual consistency without distributed transactions, and workflow code that stays focused on the business process rather than cleanup choreography.
Key tradeoffs
What we gained
No infrastructure to manage: Skipper runs inside your service. No separate cluster to deploy, monitor, or page on.
Uses existing dependencies: If your service depends on MySQL, Skipper uses that MySQL instance. If it uses Airbnb’s Unified Data Store, Skipper uses that. No new data stores or failure modes.
Simple programming model: Workflows are Java/Kotlin classes. Actions are method calls. Developers use familiar tools and debugging workflows.
Independent scaling: Each service manages its own workflow processing. High load on one service’s workflows doesn’t affect others.
What we traded off
Determinism requirement: The replay model requires deterministic workflow methods, which can be unintuitive for developers new to the pattern.
At-least-once execution: Actions may execute more than once in edge cases (crash after execution but before checkpoint). Actions should be idempotent.
Evolution complexity: Changing a workflow’s structure can break in-flight workflows. Teams need versioning strategies for workflow evolution.
These tradeoffs are inherent to the embedded model; teams needing cross-language support or cross-service orchestration may find a dedicated orchestration system more appropriate.
Production impact
Skipper has been running in production for more than a year, powering 15+ use cases across insurance, payments, media, infrastructure, incentives, and wallet teams. Use cases include multi-step claim processing, policy lifecycle management, resilient transaction orchestration, and scheduled financial operations that can span days or weeks. The Media Foundation team uses Skipper to coordinate video processing pipelines — validation, transcoding, thumbnail generation — surviving pod restarts across multi-hour jobs. Infrastructure teams rely on it for durable Flink job lifecycle management and reliable data pipeline CRUD operations. Across all domains, Skipper guarantees that every workflow reaches a terminal state, even through infrastructure failures, deployments, and infrastructure disruptions. At peak, Skipper has scaled to 10,000 workflows per second on Amazon DynamoDB, enabled by its lean execution model.
Lessons learned
What worked well. The embedded model reduces operational burden dramatically. Teams adopt Skipper without new infrastructure, deployment procedures, or on-call rotations. Supporting multiple storage backends (MySQL and our internal UDS) means that no team is blocked by database incompatibility. And the simple API (“actions are checkpointed, workflows must be deterministic”) accelerated learning, with workflow code reading like straightforward business logic.
What we’d reconsider. Workflow evolution remains the biggest friction point. While we have versioning patterns (create new method versions, migrate traffic, deprecate old versions), better tooling — automated compatibility checking, migration assistants, runtime versioning support — would smooth the experience. Debugging replayed workflows also requires mental model adjustment: engineers must understand that log timestamps and call sequences reflect replays, not original execution. Better observability tooling, particularly replay visualization, would help.
Conclusion
Durable workflow execution is a fundamental capability for reliable distributed systems. Skipper represents a specific point in the design space: an embedded engine that trades centralized orchestration for operational simplicity, running inside services rather than alongside them, using existing databases, and providing a straightforward Java/Kotlin programming model.
This approach won’t fit every situation. But for services seeking durable execution without infrastructure overhead, particularly those where minimizing dependencies is paramount, the embedded model offers compelling advantages. The core insight — that replay-based execution with checkpointed actions can provide durability without coordination services — generalizes beyond Airbnb’s implementation to anywhere you’re building long-running, failure-prone workflows.
If this type of work interests you, check out some of our open roles.
Acknowledgements
Skipper wouldn’t have been possible without the support and contributions of many people across different teams. Special thanks to Navjot Sidhu, Musaab At-Taras, Mini Atwal, Gary Leung, Harshit Gupta, Alex Zhang, Gerum Haile.
All product names, logos, and brands are property of their respective owners. All company, product and service names used in this website are for identification purposes only. Use of these names, logos, and brands does not imply endorsement